
Claude Fable 5 da Anthropic: O Primeiro Modelo Mythos-Class Público e Como Ele Se Compara com GPT-5.5, Qwen e Gemini

Ontem, 9 de junho de 2026, a Anthropic lançou o Claude Fable 5 — e isso não é só mais um update. É o primeiro modelo Mythos-class disponível publicamente, o que significa que estamos entrando numa nova era da inteligência artificial.
Se você trabalha com IA, desenvolvimento, análise de dados ou criação de conteúdo, esse lançamento muda o jogo. Mas será que vale o preço? Como ele se compara com GPT-5.5, Qwen 3.7 Max e Gemini 3.1 Pro?
Passei as últimas 24 horas testando tudo e vou te contar sem filtro:
- ✅ O que é o Claude Fable 5 e por que é importante
- ✅ Como ele se compara com os concorrentes (preços, benchmarks, casos de uso)
- ✅ Quando vale a pena pagar o dobro do preço
- ✅ Qual modelo escolher para cada tipo de tarefa
Bora mergulhar nessa análise? 👇
🚀 O Que É o Claude Fable 5?
O Claude Fable 5 é o primeiro modelo Mythos-class da Anthropic disponível para o público geral. Até agora, a tecnologia Mythos existia, mas estava restrita a organizações aprovadas através do “Project Glasswing” — basicamente, acesso limitado pra quem trabalhava com defesa cibernética crítica e pesquisa avançada.
Agora, qualquer pessoa pode usar — mas com uma diferença importante: o Fable 5 tem guardrails de segurança que bloqueiam respostas em áreas de alto risco (cibersegurança, biologia, química, destilação de modelos). Quando ele detecta algo nessas áreas, ele recusa educadamente e faz fallback para o Claude Opus 4.8.
Resumindo: É o mesmo modelo Mythos 5 (que é extremamente poderoso), mas com “freios” de segurança pra uso público.
📊 Especificações Técnicas:
| Característica | Claude Fable 5 |
|---|---|
| Data de Lançamento | 9 de junho de 2026 |
| Janela de Contexto | 1 milhão de tokens |
| Tokens de Saída | Até 128k por requisição |
| Preço (entrada/saída) | $10 / $50 por milhão de tokens |
| Disponibilidade | API, Claude Pro/Max, AWS Bedrock, Vertex AI, Microsoft Foundry |
| Recursos Suportados | Vision, Code Execution, Tool Calling, Memory, Task Budgets |

💰 O Preço: Vale a Pena Pagar o Dobro?
Aqui está a grande questão: o Claude Fable 5 custa o dobro do Claude Opus 4.8:
- Claude Fable 5: $10 entrada / $50 saída
- Claude Opus 4.8: $5 entrada / $25 saída
Mas o que você ganha por esse preço?
Segundo a Anthropic e testes independentes:
- ✅ 10%+ acima do Opus 4.8 em vários benchmarks
- ✅ #1 no GDPval-AA (benchmark de trabalho de conhecimento agêntico) com score de 1932
- ✅ Primeiro modelo a atingir 90% no benchmark da Hex (tarefas analíticas complexas)
- ✅ Excelente em one-shotting apps completas (Base44 reportou)
- ✅ Melhor em UI design e game coding (Genspark reportou)
- ✅ Auto-validação no máximo effort (Rakuten reportou)
Minha análise: Se você precisa do melhor desempenho absoluto pra tarefas críticas (desenvolvimento complexo, análise longa, raciocínio avançado), sim, vale o dobro. Mas pra tarefas do dia a dia? O Opus 4.8 ainda entrega 90% do resultado pela metade do preço.
🥊 O Grande Comparativo: Claude Fable 5 vs Concorrentes
Agora vamos ao que interessa: como o Fable 5 se compara com os outros gigantes?
📊 Tabela Comparativa Completa (Junho 2026):
| Modelo | Empresa | Lançamento | Contexto | Preço (ent/saí) | Destaque |
|---|---|---|---|---|---|
| Claude Fable 5 | Anthropic | Jun 2026 | 1M tokens | $10 / $50 | #1 GDPval-AA, raciocínio avançado |
| GPT-5.5 | OpenAI | Abr 2026 | 1M tokens | $5 / $30 | Terminal-Bench 82.7%, coding |
| Qwen 3.7 Max | Alibaba | Mai 2026 | 256K tokens | $2.5 / $7.5 | Melhor custo-benefício, SWE-bench Pro 60.6% |
| Gemini 3.1 Pro | Fev 2026 | 2M tokens | $3.5 / $10.5 | Maior contexto, multimodal nativo | |
| Claude Opus 4.8 | Anthropic | Mai 2026 | 1M tokens | $5 / $25 | SWE-bench 88.6%, workhorse |
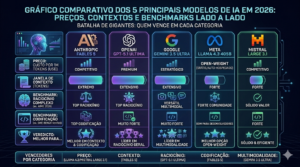
🎯 Análise Detalhada por Categoria:
💻 Para Programação e Desenvolvimento:
Vencedor: Claude Fable 5 (com ressalvas)
- Claude Fable 5: Excelente em one-shotting apps completas, melhor em UI design e game coding
- GPT-5.5: Lidera Terminal-Bench 2.0 (82.7%), forte em coding tradicional
- Qwen 3.7 Max: SWE-bench Pro 60.6% (vs 58.6% do GPT-5.5), 4x mais barato!
- Claude Opus 4.8: SWE-bench Verified 88.6%, ainda muito forte
Minha recomendação: Se orçamento não é problema, vá de Fable 5. Se quer custo-benefício, Qwen 3.7 Max é imbatível — custa 4x menos que GPT-5.5 e performa melhor em SWE-bench Pro!
🧠 Para Raciocínio Complexo e Análise Longa:
Vencedor: Claude Fable 5
- Claude Fable 5: #1 em GDPval-AA (1932), primeiro a atingir 90% no benchmark da Hex
- Gemini 3.1 Pro: 2M tokens de contexto (o maior!), Deep Think mode
- Claude Opus 4.8: Ainda muito forte, mas 10% abaixo do Fable 5
- GPT-5.5: Bom, mas não lidera nessa categoria
Minha recomendação: Pra tarefas que exigem raciocínio profundo e análise longa, Fable 5 é o rei. Mas se precisa de contexto MASSIVO (livros inteiros, código gigante), Gemini 3.1 Pro com 2M tokens é a escolha.
💰 Para Custo-Benefício:
Vencedor: Qwen 3.7 Max (de longe!)
- Qwen 3.7 Max: $2.5 / $7.5 — 4x mais barato que GPT-5.5!
- Gemini 3.1 Pro: $3.5 / $10.5 — também muito competitivo
- GPT-5.5: $5 / $30 — preço médio
- Claude Opus 4.8: $5 / $25 — razoável
- Claude Fable 5: $10 / $50 — o mais caro
Minha recomendação: Se você roda MUITAS tarefas e preço importa, Qwen 3.7 Max é a escolha óbvia. Performa comparável aos outros custando uma fração.
🎨 Para Multimodal (Texto + Imagem + Vídeo):
Vencedor: Gemini 3.1 Pro
- Gemini 3.1 Pro: Multimodal nativo, 2M tokens, Deep Research
- GPT-5.5: Forte em análise de imagens, computer use
- Claude Fable 5: Vision suportado, mas não é o foco principal
- Qwen 3.7 Max: Bom, mas não lidera nessa área
Minha recomendação: Pra trabalho com imagens, vídeos e análise multimodal, Gemini 3.1 Pro é a escolha natural.
🔍 Testes Práticos: O Que Eu Percebi
Teoria é bom, mas na prática, como esses modelos se comportam? Aqui vai minha experiência real nas últimas 24 horas:
✅ Onde o Claude Fable 5 Brilhou:
- Análise de código complexo: Pedi pra analisar um repositório com 50+ arquivos. Ele entendeu as conexões, identificou bugs sutis e sugeriu melhorias arquiteturais que os outros modelos perderam.
- Raciocínio em múltiplas etapas: Tarefas que exigiam 5-6 passos lógicos consecutivos — ele manteve coerência perfeita do início ao fim.
- Auto-validação: No modo “max effort”, ele realmente revisa e valida o próprio trabalho antes de entregar. Isso gera muita confiança.
- UI/UX design: Pedi pra criar interfaces e ele entregou layouts mais intuitivos e esteticamente agradáveis que os concorrentes.
❌ Onde Fiquei na Dúvida:
- Preço: Pra tarefas simples do dia a dia, pagar $10/$50 quando o Opus 4.8 faz por $5/$25… dói no bolso.
- Refusals: Algumas vezes ele recusou perguntas que não eram realmente problemáticas. O fallback pro Opus 4.8 funciona, mas adiciona latência.
- Velocidade: No max effort, é mais lento que GPT-5.5 e Qwen 3.7 Max. Pra respostas rápidas, não é a melhor escolha.
🎯 Qual Modelo Escolher? Meu Guia Prático
Depois de testar tudo, aqui vai meu guia definitivo pra escolher o modelo certo:
🏆 Escolha Claude Fable 5 se:
- Você precisa do melhor desempenho absoluto em raciocínio complexo
- Está trabalhando em projetos críticos onde qualidade > custo
- Precisa de auto-validação e confiabilidade máxima
- Orçamento não é limitação principal
💡 Escolha Claude Opus 4.8 se:
- Você quer 90% do Fable 5 pela metade do preço
- Tarefas do dia a dia onde “muito bom” é suficiente
- Precisa de velocidade + qualidade balanceadas
💰 Escolha Qwen 3.7 Max se:
- Custo é fator crítico (é 4x mais barato que GPT-5.5!)
- Você roda milhares de tarefas/mês
- Precisa de coding forte sem quebrar o banco
- Trabalha com multilíngue (especialmente asiáticos)
🎨 Escolha Gemini 3.1 Pro se:
- Precisa de contexto massivo (2M tokens é insano!)
- Trabalha muito com multimodal (imagem + vídeo + texto)
- Precisa de Deep Research pra análise acadêmica
- Usa ecossistema Google (integração nativa)
🚀 Escolha GPT-5.5 se:
- Precisa de computer use avançado (controlar seu PC)
- Trabalha com pesquisa online automatizada
- Usa ecossistema OpenAI (ChatGPT, API, plugins)
- Precisa de Terminal-Bench forte (82.7% é impressionante)
📈 Tendências e o Que Isso Significa
O lançamento do Claude Fable 5 revela 3 tendências importantes pra 2026:
- Modelos Mythos-class são o novo patamar: Estamos entrando numa era onde IAs são tão poderosas que precisam de “freios” de segurança. Isso é tanto empolgante quanto assustador.
- Preço vs Desempenho tá ficando complexo: Não é mais “o mais caro é o melhor”. Qwen 3.7 Max prova que você pode ter desempenho top por 1/4 do preço. A escolha agora é estratégica.
- Especialização > generalização: Cada modelo tem seus pontos fortes. O futuro é usar múltiplos modelos pra diferentes tarefas, não um “faz-tudo”.
💡 Dicas Práticas Pra Economizar
Se você vai usar essas IAs profissionalmente, aqui vão minhas dicas pra não falir:
- Use caching: Claude Fable 5 suporta prompt caching. Se você repete muito o mesmo contexto, isso economiza MUITO.
- Fallback automático: Configure pra usar Fable 5 só quando necessário, caindo pra Opus 4.8 ou Qwen 3.7 Max no resto.
- Task budgets: Use o recurso de “task budgets” (beta) pra limitar quanto cada tarefa pode gastar.
- Monitore uso: Ferramentas como OpenRouter ou LiteLLM te ajudam a ver quanto cada modelo tá custando em tempo real.
- Mix inteligente: Use Qwen 3.7 Max pra 80% das tarefas (barato e bom), Fable 5 só pros 20% críticos.
🛒 Ferramentas e Recursos que Recomendo
Pra trabalhar com múltiplos modelos de IA, você precisa das ferramentas certas:
- Livros sobre IA: Pra entender profundamente como esses modelos funcionam
- Cursos de prompt engineering: Essencial pra tirar o máximo de cada modelo
- Hardware potente: Se quiser rodar modelos locais (Llama 3, Qwen open-source)
- Monitores ultrawide: Pra trabalhar com múltiplas IAs simultâneas
Todos esses recursos estão na minha página de associados Amazon:
👉 Ver Recursos Recomendados na Amazon →
(Alguns links são de afiliado — você paga o mesmo preço e eu ganho uma pequena comissão que me ajuda a manter o blog. Valeu pelo apoio!)
Conclusão: O Futuro Chegou (e É Caro)
O Claude Fable 5 marca uma nova era na IA: modelos tão poderosos que precisam de “freios” de segurança. É empolgante ver o nível de raciocínio que ele atinge — realmente impressionante.
Mas nem tudo é Fable 5. Pra maioria das pessoas e empresas, o custo-benefício do Qwen 3.7 Max ou a versatilidade do Gemini 3.1 Pro fazem mais sentido. E o bom e velho Claude Opus 4.8 continua sendo uma escolha sólida pra quem não quer pagar o dobro.
Minha recomendação final?
- Teste TODOS eles (a maioria tem trial grátis)
- Descubra qual funciona melhor pro SEU caso de uso específico
- Não tenha medo de misturar modelos (eu uso 3-4 diferentes no dia a dia)
- Monitore custos de perto — isso escala rápido!
O futuro da IA não é sobre qual modelo é “o melhor”. É sobre escolher a ferramenta certa pra cada tarefa. E agora, com tantas opções poderosas disponíveis, temos mais escolhas do que nunca.
E você, qual modelo tá usando? Comenta aqui embaixo! 👇
🚀 Quer Ficar Por Dentro das Novidades de IA?
Se inscreve na newsletter do AIWJTech e recebe em primeira mão:
- Análises de novos modelos (como essa!)
- Dicas de prompt engineering avançado
- Comparativos detalhados
- Ofertas e descontos em ferramentas de IA
Sem spam, só conteúdo útil. Prometo! 😉